

Actualmente nosotros mismos les proporcionamos a Google y Facebook nuestra información personal (de incalculable valor para ellos), y absolutamente gratis. ¿Es posible acabar con esta injusticia? ¿Y quién va a ayudarnos a hacerlo?
Jennifer Lyn Morone, una artista americana, piensa que este es el estado en el que vive la mayoría de la gente. Para obtener servicios online gratuitos, lamenta, los usuarios entregan información privada a las empresas tecnológicas. “Los datos personales son mucho más valiosos de lo que se cree”, dice. Para poner de relieve esta lamentable situación, Morone ha recurrido a lo que ella llama “capitalismo extremo”: se registró como empresa en Delaware en un esfuerzo por explotar sus datos personales para obtener beneficios económicos. Creó dossiers que contenían diferentes subconjuntos de datos, que expuso en una galería de Londres en 2016 y puso a la venta a partir de 100 libras (135 dólares). Toda la colección, incluidos los datos sobre su salud así como su número de la seguridad social, podían obtenerse por 7.000 libras esterlinas.
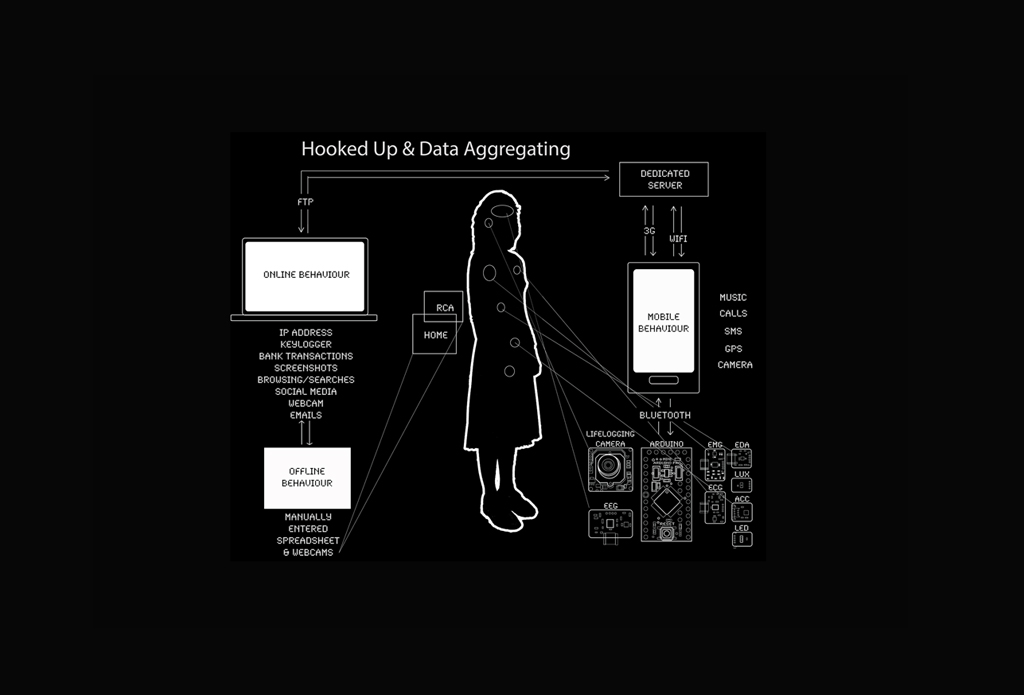
Tan solo unos pocos compradores han aceptado esta oferta, lo que a ella le parece “realmente absurdo”. Sin embargo, si el trabajo de la artista es anticiparse al Zeitgeist, la Sra. Morone estaba totalmente de acuerdo: este año el mundo ha descubierto que algo está podrido en la economía de datos. Desde que en marzo se supo que Cambridge Analytica, una consultora política, había adquirido datos sobre 87 millones de usuarios de Facebook de forma ilegal, las voces que pedían un replanteamiento del tratamiento de los datos personales en la red no han hecho más que aumentar. Incluso Angela Merkel, la canciller alemana, ha pedido recientemente que se ponga un precio a los datos personales, pidiendo a los investigadores que encuentren soluciones.
Dada la situación actual de los asuntos digitales, en la que la recogida y explotación de datos personales está dominada por las grandes empresas tecnológicas, el enfoque de la Sra. Morone, en el que los particulares ponen sus datos a la venta, parece poco probable que se haga realidad. Pero, ¿qué pasaría si la gente controlara realmente sus datos, y los gigantes de la tecnología tuvieran que pagar por acceder a ellos? ¿Cómo sería una economía de datos de este tipo?
No sería la primera vez que un recurso económico importante ha pasado de ser simplemente usado a ser propiedad y comercializado; lo mismo ha ocurrido con la tierra y el agua, por ejemplo. Sin embargo, la información digital parece un candidato poco probable para ser asignada por los mercados. A diferencia de los recursos físicos, los datos personales son un ejemplo de lo que los economistas llaman bienes “no rivales”, es decir, que pueden utilizarse más de una vez. De hecho, cuanto más se utilicen, mejor para la sociedad. Y las fugas frecuentes muestran lo difícil que puede ser controlar los datos. Pero otro precedente histórico podría servir de modelo, y también encaja con las preocupaciones contemporáneas sobre el “tecnofeudalismo”, argumentan Jaron Lanier, un pionero de la realidad virtual, y Glen Weyl, un economista de la Universidad de Yale, quienes trabajan para Microsoft Research.

El trabajo, al igual que los datos, es un recurso difícil de precisar. Durante la mayor parte de la historia de la humanidad, los trabajadores no han recibido una remuneración adecuada a cambio de su trabajo. Incluso cuando la gente era libre de vender su mano de obra, se necesitaron décadas para que los salarios alcanzaran niveles aceptables. La historia no se repetirá, pero lo más probable es que se parezca un poco, predice Weyl en “Radical Markets”, un nuevo y provocativo libro que ha escrito junto con Eric Posner de la Universidad de Chicago. Este sostiene que en la era de la inteligencia artificial, tiene sentido tratar los datos como una forma de trabajo.
Para entender por qué, es útil tener en cuenta que “inteligencia artificial” es algo así como un nombre equivocado. Los señores Weyl y Posner lo llaman “inteligencia colectiva”: la mayoría de los algoritmos de IA necesitan ser entrenados empleando montones de ejemplos generados por humanos, en un proceso llamado aprendizaje automático. A menos que sepan cuáles son las respuestas correctas (proporcionadas por los humanos), los algoritmos no pueden traducir idiomas, entender el habla o reconocer objetos en imágenes. Por lo tanto, los datos proporcionados por los seres humanos pueden considerarse como una forma de trabajo que potencia la IA. A medida que la economía de datos crezca, este trabajo de datos adoptará muchas formas. Gran parte de ella será pasiva, ya que la gente participa en todo tipo de actividades - como publicaciones en medios sociales, escuchar música, recomendar restaurantes - que generan los datos necesarios para impulsar nuevos servicios. Pero el trabajo de datos de algunas personas será más activo, ya que tomarán decisiones (como etiquetar imágenes o conducir un coche a través de una ciudad muy concurrida) que pueden utilizarse como base para la formación de los sistemas de IA.
Sin embargo, independientemente de que estos datos se generen de forma activa o pasiva, pocas personas tendrán el tiempo o la inclinación necesarios para hacer un seguimiento de toda la información que generan, o estimar su valor. Incluso aquellos que lo hagan carecerán del poder de negociación para alcanzar un buen acuerdo con las empresas de inteligencia artificial. Sin embargo, la historia del trabajo ofrece una pista sobre cómo podrían evolucionar las cosas: porque históricamente, si los salarios subieron a niveles aceptables, se debió principalmente a los sindicatos. Del mismo modo, el Sr. Weyl espera ver el surgimiento de lo que él llama “sindicatos de trabajadores de datos”, organizaciones que sirven como guardianes de los datos de las personas. Al igual que sus predecesores, negociarán las tarifas, controlarán el trabajo de datos de los miembros y garantizarán la calidad de los datos que generan, por ejemplo, manteniendo las puntuaciones de reputación. Los sindicatos podrían canalizar el trabajo de los especialistas a sus miembros e incluso organizar huelgas, por ejemplo bloqueando el acceso para ejercer influencia sobre una empresa que emplea los datos de sus miembros. Del mismo modo, los sindicatos de datos podrían ser canales que canalizaran las contribuciones de datos de los miembros, todo ello al mismo tiempo que los rastrean y facturan a las empresas de inteligencia artificial que se beneficiaban de ellos.
Todo esto puede sonar a ciencia ficción. ¿Por qué deberían Google y Facebook, por ejemplo, abandonar su actual modelo de negocio de utilizar datos gratuitos para vender publicidad online dirigida? En 2017 ganaron un total combinado de 135.000 millones de dólares en publicidad. Si tuvieran que compensar a la gente por sus datos, su rentabilidad sería mucho menor. Mientras tanto, las startups como CitizenMe y Datacoup, que pueden considerarse como las primeras formas de unión de datos, no han avanzado mucho hasta ahora. Sin embargo, en otros rincones de la industria, los gigantes de la tecnología ya pagan por los datos, aunque tienen cuidado de no hablar demasiado sobre ellos. Principalmente a través de la subcontratación de empresas, emplean ejércitos de calificadores y moderadores para comprobar la calidad de sus algoritmos y eliminar el contenido ilegal u ofensivo. Otras empresas utilizan plataformas de trabajo en grupo, como la de Amazon Mechanical Turk, para cultivar el trabajo de datos, como el etiquetado de imágenes. Mighty AI, una startup con sede en Seattle, paga a miles de trabajadores online para que etiqueten imágenes de escenas callejeras que son utilizadas para entrenar a los algoritmos con los que funcionan los coches autónomos.

Además, si la IA está a la altura de las expectativas, se producirá una demanda de más y mejores datos. A medida que los servicios de inteligencia artificial se hagan más sofisticados, los algoritmos tendrán que alimentarse con una información digital de mayor calidad, que la gente solo puede proporcionar si es pagada por ella. Una vez que una gran empresa de tecnología comience a pagar por los datos, es posible que otras se vean obligadas a seguir su ejemplo.
Tratar los datos como mano de obra significa que es probable que los márgenes de beneficio de los gigantes tecnológicos se vean reducidos, pero su negocio en general podría crecer. Y los trabajadores estarán al mando, al menos de forma parcial. Sus mañanas podrían comenzar con la revisión de un tablero de mandos proporcionado por su sindicato de trabajo de datos, mostrando una lista personalizada de trabajos disponibles: desde ver publicidad (la cámara del ordenador recoge las reacciones faciales) hasta traducir un texto a un idioma poco común, pasando por explorar un edificio virtual para ver lo fácil que es navegar por él. El tablero de instrumentos también puede enumerar las ganancias pasadas, mostrar las calificaciones y sugerir nuevas habilidades.
Sin embargo, aún queda mucho por hacer para que los datos personales sean ampliamente considerados como mano de obra y pagados como tales. En primer lugar, será necesario un marco jurídico adecuado para fomentar la aparición de una nueva economía de datos. El nuevo Reglamento General de Protección de Datos de la Unión Europea, que entró en vigor en mayo, ya otorga a los ciudadanos amplios derechos para comprobar, descargar e incluso eliminar sus datos personales que obran en poder de las empresas. En segundo lugar, la tecnología para hacer un seguimiento de los flujos de datos debe ser mucho más eficaz. Las herramientas para calcular el valor de los datos particulares para un servicio de IA todavía se encuentran en sus primeras etapas de desarrollo.
En tercer lugar, y lo más importante, la gente tendrá que desarrollar una “conciencia de clase” como trabajadores de datos. La mayoría de las personas afirman que desean que su información personal sea protegida, pero luego la intercambian por casi nada, lo que se conoce como la “paradoja de la privacidad”. Sin embargo, las cosas podrían estar cambiando: más del 90% de los estadounidenses creen que es importante tener el control de quién puede obtener datos sobre ellos, según el Pew Research Centre, un centro de investigación.
Incluso si la gente obtuviera dinero a cambio de sus datos, dicen los escépticos, no obtendrían mucho. Si Facebook repartiera sus beneficios entre todos sus usuarios mensuales, por ejemplo, cada uno recibiría solo 9 dólares al año. Sin embargo, estos cálculos no reconocen que la era de los datos no ha hecho más que empezar. La IA suele ser comparada con la electricidad, y cuando la electrificación comenzó a finales del siglo XIX, ciudades enteras utilizaban la misma cantidad de energía que una sola familia en la actualidad.
¿No sería esta economía de datos enormemente desigual? Los datos de algunas personas seguramente valdrán mucho más que los de otras. No obstante, el Sr. Weyl defiende que las habilidades necesarias para generar datos valiosos podrían estar más difundidas de lo que se cree, por lo que el trabajo con datos podría alterar la jerarquía estándar del capital humano. De una forma u otra, las sociedades tendrán que encontrar un mecanismo para distribuir la riqueza creada por la IA. Tal y como están las cosas ahora, la mayor parte de la información corresponde a las grandes destilerías de datos. A menos que esto cambie, la desigualdad social podría volver a los niveles medievales, advierte el Sr. Weyl. Si eso acaba sucediendo, no es irrazonable asumir que algún día, los trabajadores de datos del mundo acabarán uniéndose.